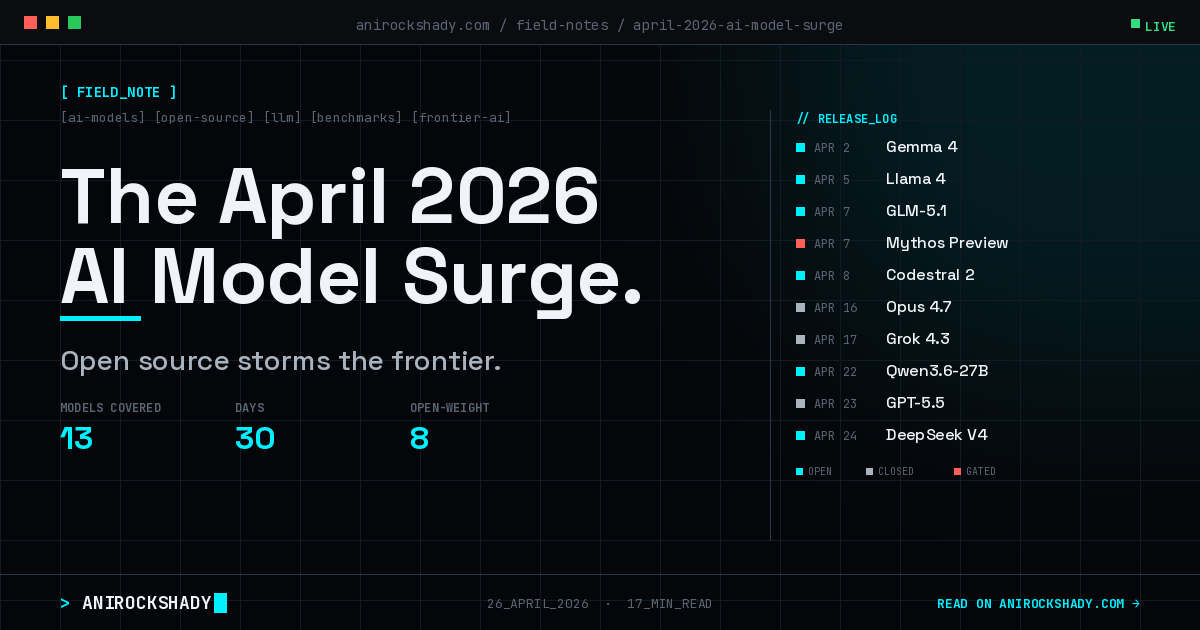
April 2026 produced more significant model releases in 30 days than most years produce in twelve. OpenAI retrained GPT from scratch for the first time since GPT-4.5. Anthropic built a model so capable it refused to ship it publicly. Meta dropped the first open-weight natively multimodal models with a 10-million-token context window. DeepSeek returned with a 1.6-trillion-parameter beast priced at MIT-license rates. And a Chinese startup most engineers hadn't heard of claimed the top slot on SWE-bench Pro. What follows is every model that mattered, what the benchmarks actually mean, and the signal hiding under the noise.
The Landscape at a Glance
| Model | Released | Type | License | Context | SWE-bench Verified |
|---|---|---|---|---|---|
| Claude Mythos Preview | Apr 7 | Proprietary (restricted) | Closed | - | ~93.9% (est.) |
| Claude Opus 4.7 | Apr 16 | Proprietary | Closed | 1M | 87.6% |
| GPT-5.5 | Apr 23 | Proprietary | Closed | 1M | - |
| Grok 4.3 Beta | Apr 17 | Proprietary | Closed | 2M | - |
| Qwen3.6-Max-Preview | Apr 2 | Proprietary | Closed | - | - |
| Llama 4 Scout | Apr 5 | Open weight | Meta Custom | 10M | - |
| Llama 4 Maverick | Apr 5 | Open weight | Meta Custom | 1M | - |
| Gemma 4 (31B Dense) | Apr 2 | Open weight | Apache 2.0 | 256K | - |
| GLM-5.1 | Apr 7 | Open weight | MIT | 200K | 58.4% (Pro) |
| DeepSeek V4-Pro | Apr 24 | Open weight | MIT | 1M | 80.6% |
| DeepSeek V4-Flash | Apr 24 | Open weight | MIT | 1M | 79.0% |
| Qwen3.6-27B | Apr 22 | Open weight | Apache 2.0 | - | 77.2% |
| Mistral Codestral 2 | Apr 8 | Open weight | Apache 2.0 | 256K | - |
| NVIDIA Ising | Apr 14 | Open (quantum domain) | Open | - | N/A |
Proprietary Frontier: The Big Labs
Claude Mythos Preview - The Model They Won't Ship
Anthropic announced Claude Mythos Preview on April 7, 2026, and immediately stated it has "no plans to make Mythos Preview generally available" due to cybersecurity risk. The benchmarks make the decision legible: Mythos scores 93.9% on SWE-bench Verified, 97.6% on USAMO mathematical olympiad problems, and 94.6% on GPQA Diamond. Those scores place it in a different tier from any publicly accessible model. Anthropic used Mythos internally to identify thousands of zero-day vulnerabilities across every major operating system and browser before the announcement.
Access is gated through Project Glasswing, a restricted cybersecurity initiative launched alongside the model. Launch partners include AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Approximately 40 additional organizations building or maintaining critical software infrastructure have extended access.
The Glasswing framing is deliberate: Anthropic's stated position is that defenders need a head start before a model this capable reaches general availability. Security researcher Bruce Schneier noted on his blog that this is "the first time a major lab has withheld a flagship model not for commercial reasons but for safety ones." Whether the restriction holds, and for how long, is an open question. Fortune, which broke the story in late March before the official announcement, suggests a stripped-down form may ship eventually.
- Anthropic Project Glasswing: anthropic.com/glasswing
- Mythos Preview post: red.anthropic.com/2026/mythos-preview
Claude Opus 4.7 - The Generally Available King
Anthropic shipped Claude Opus 4.7 on April 16, 2026, the publicly available flagship and the model most production teams will actually integrate. The headline improvement is agentic coding: SWE-bench Pro jumped from 53.4% on Opus 4.6 to 64.3%, and SWE-bench Verified moved from 80.8% to 87.6%. Anthropic describes this as "3x more production tasks resolved" in internal testing.
Three engineering-specific additions shipped with 4.7:
Vision ceiling raised. Maximum image resolution increased from 1568px / 1.15MP to 2576px / 3.75MP. Relevant for visual reasoning over engineering diagrams, dense screenshots, and document-heavy workflows.
Task budgets. A new primitive: the model receives a rough token budget for an agentic loop (thinking, tool calls, and output) and uses a running countdown to prioritize and finish gracefully within it. Gives operators predictable cost control on long-horizon autonomous tasks.
Effort level extended. Opus 4.7 adds xhigh, a new effort tier between high and max. Anthropic recommends xhigh for coding and agentic workloads. For most intelligence-sensitive tasks, high remains the baseline recommendation.
Pricing stays at $5.00 / $25.00 per million input/output tokens - same as Opus 4.6. One migration caveat: the new tokenizer may produce 1x to 1.35x more tokens for the same text content depending on content type. Budget for up to a 35% cost increase on tokenization-heavy workloads before assuming cost parity.
Opus 4.7 is available on the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
- Anthropic announcement: anthropic.com/news/claude-opus-4-7
- VentureBeat coverage: venturebeat.com
GPT-5.5 - Natively Omnimodal, Retrained From Scratch
OpenAI released GPT-5.5 on April 23, 2026 - codenamed "Spud" internally - the first fully retrained base model since GPT-4.5. Every 5.x release before it was a refinement of the same base weights. GPT-5.5 is a clean rebuild.
The defining architectural change: native omnimodal processing. Text, images, audio, and video are processed in a single unified model, end-to-end. No modality-specific adapters, no routing. A single set of weights handles all input types.
Benchmark performance on OpenAI's reported evaluations:
| Benchmark | GPT-5.5 | GPT-5.5 Pro | What It Measures |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | - | Agentic coding (leads all public models) |
| GDPval | 84.9% | - | Knowledge work across 44 occupations |
| OSWorld-Verified | 78.7% | - | Operating real computer environments autonomously |
| Tau2-bench Telecom | 98.0% | - | Complex customer-service multi-step workflows |
| FrontierMath Tier 4 | - | 39.6% | Postdoctoral-level math (≈2x Claude Opus 4.7's 22.9%) |
| ARC-AGI-2 | 85% | - | Fluid reasoning on novel abstract grid puzzles |
At 85% on ARC-AGI-2, GPT-5.5 becomes the first model to reach the benchmark's grand prize threshold. The human average on ARC-AGI-2 is 60% - GPT-5.5 clears it by 25 points. This is the same benchmark that frontier models were scoring in the 30–40% range as recently as late 2025.
Pricing: $5.00 / $30.00 per million input/output tokens - doubled from GPT-5.4's $2.50/$15. OpenAI claims a 20% effective cost increase once token efficiency gains are factored in. Available to ChatGPT Plus, Pro, Business, and Enterprise on April 23; API access opened April 24.
- OpenAI release post: openai.com/index/introducing-gpt-5-5
- System card: deploymentsafety.openai.com/gpt-5-5
- TechCrunch: techcrunch.com
Grok 4.3 Beta - Video, Documents, Spreadsheets
xAI entered April with Grok 4.20 already in market (released March 31) and shipped Grok 4.3 Beta on April 17 for SuperGrok Heavy subscribers. Grok 4.20 carries a 2M token context window - the largest of any publicly available model this month.
Grok 4.3's additions are output-format focused: the model can generate downloadable PDFs, fully populated spreadsheets, and PowerPoint decks directly from conversation, and processes video content natively. The practical upshot: document-heavy enterprise workflows without a separate formatting layer.
On the Artificial Analysis Intelligence Index, Grok 4.20 Reasoning scores 49 - above the median for reasoning models in a comparable price tier (median: 33), but below the 57-point cluster occupied by Claude Opus 4.7, GPT-5.4, and Gemini 3.1 Pro. Grok 4.20 did climb to number-one positions on Text Arena for healthcare and BridgeBench for reasoning specifically, outperforming Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro in those categories as of mid-April.
- xAI release: x.ai/news/grok-4
Qwen3.6-Max-Preview - Alibaba's Closed-Source Pivot
Alibaba released Qwen3.6-Max-Preview in April as its most capable model to date, leading six major coding benchmarks and posting gains in world knowledge and instruction following over Qwen3.6-Plus. It is proprietary, hosted, with no open weights. API access is compatible with both OpenAI and Anthropic specifications.
This marks a strategic shift worth noting: Alibaba's Qwen series was historically open-source by default. Qwen3.5-Omni and Qwen3.6-Plus were both released in April as proprietary, access limited to the Alibaba Cloud platform. Qwen3.6-Max-Preview continues that trend. The open-weight releases from Alibaba in April - Qwen3.6-Plus (April 2) and Qwen3.6-27B (April 22) - are distinct products, not Max-Preview.
Open-Weight Releases: The Models You Can Actually Run
Llama 4 Scout and Maverick - Meta's 10M-Context Bet
Meta released Llama 4 Scout and Llama 4 Maverick on April 5, 2026 - the first open-weight natively multimodal models built on a Mixture-of-Experts architecture.
| Llama 4 Scout | Llama 4 Maverick | |
|---|---|---|
| Active Parameters | 17B | 17B |
| Experts | 16 | 128 |
| Context Window | 10M tokens | 1M tokens |
| Multimodal | Yes (vision) | Yes (vision) |
| Hardware Minimum | ~12GB VRAM | ~48GB VRAM |
The 10M token context on Scout is the number that earned the most attention: entire codebases, extended document archives, or long-form research corpora as a single prompt. Maverick's 128-expert MoE is the broader model, comparable to Gemini 2.0 Flash in multimodal benchmarks per Meta's reporting.
One caveat earned independent media attention after release: Meta submitted a non-public experimental version of Maverick to LMArena to establish benchmark claims, then shipped different weights publicly. Independent researchers identified the discrepancy. The performance gap between submitted and released versions ran 1–2 percentage points on reasoning benchmarks. The incident is relevant context for any benchmark claim made via leaderboard submission.
Llama 4 weights are available at llama.com and Hugging Face under Meta's custom open-weight license.
- Meta blog: ai.meta.com/blog/llama-4-multimodal-intelligence
- Hugging Face release: huggingface.co/blog/llama4-release
Gemma 4 - Apache 2.0, Four Sizes, Native Audio
Google DeepMind released Gemma 4 on April 2, 2026 under the Apache 2.0 license - the first Gemma release to use the OSI-approved Apache 2.0 terms, meaning unrestricted commercial use with no Google-specific carve-outs.
Four model sizes ship as a single family:
| Model | Parameters | Active (MoE) | Target | Context |
|---|---|---|---|---|
| E2B | 2B | All | Mobile / on-device | 128K |
| E4B | 4B | All | Edge inference | 128K |
| 26B MoE | 26B | 3.8B | Consumer GPU | 256K |
| 31B Dense | 31B | All | Workstation | 256K |
The E2B and E4B edge models ship with native audio input for speech recognition - a first for the Gemma family. All four sizes are natively multimodal (video and images) and trained across 140+ languages. The 26B MoE activates only 3.8B parameters per forward pass, making it practical on a single mid-range consumer GPU.
- Gemma 4 blog: blog.google/innovation-and-ai/technology/developers-tools/gemma-4
- Open Source blog: opensource.googleblog.com
- Hugging Face: huggingface.co/blog/gemma4
GLM-5.1 - The MIT-Licensed Model at the Top of SWE-Bench Pro
Z.ai (Zhipu AI) released GLM-5.1 on April 7, 2026 under the MIT license - the most permissive open-source license available. No commercial restrictions. No usage limitations. Full rights to modify, redistribute, and deploy.
The architecture: 744B total parameters, Mixture-of-Experts with 40B active per forward pass, 200K token context window, 131K maximum output tokens.
The benchmark that placed it in the conversation: 58.4% on SWE-bench Pro - the first open-weight model to top that leaderboard, surpassing GPT-5.4 (57.7) and Claude Opus 4.6 (57.3). SWE-bench Pro is a harder variant of SWE-bench Verified, requiring resolution of expert-level real-world GitHub issues that are more representative of production engineering work.
Zhipu AI is the first publicly traded foundation model company in the world, with a market valuation around $31.3 billion at time of release.
- Weights on Hugging Face: huggingface.co/zai-org/GLM-5.1
- Constellation Research writeup: constellationr.com
DeepSeek V4 Flash and Pro - A Year After the Sputnik Moment
DeepSeek returned on April 24, 2026 with V4-Pro and V4-Flash - both released simultaneously as MIT-licensed open weights on Hugging Face and via the DeepSeek API.
| DeepSeek V4-Pro | DeepSeek V4-Flash | |
|---|---|---|
| Total Parameters | 1.6T | 284B |
| Active Parameters | 49B | 13B |
| Context Window | 1M tokens | 1M tokens |
| SWE-bench Verified | 80.6% | 79.0% |
| Input Pricing | $1.74 / 1M | $0.14 / 1M |
| Output Pricing | $3.48 / 1M | $0.28 / 1M |
The architectural headline: a hybrid attention mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). In the 1M-token setting, V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek V3.2. That efficiency profile is what makes a 1M context window tractable at these prices.
V4-Pro at 80.6% SWE-bench Verified sits within 0.2 points of Claude Opus 4.6 - though by April 24, Opus 4.7 had already taken the lead at 87.6%, shipping eight days earlier. V4-Flash at $0.14 per million input tokens and 79.0% SWE-bench Verified is the more disruptive number: near-frontier coding performance at commodity pricing. The gap between "self-hosted open-source" and "pay-per-token proprietary API" has effectively closed for software engineering workloads.
- DeepSeek API release notes: api-docs.deepseek.com/news/news260424
- V4-Pro on Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- V4-Flash on Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- Bloomberg: bloomberg.com
Qwen3.6-27B - 27 Billion Parameters Beating 397 Billion
Alibaba's Qwen team released Qwen3.6-27B on April 22, 2026 under Apache 2.0. It is a dense model - all 27 billion parameters active on every forward pass, no expert routing, no MoE overhead.
The claim: Qwen3.6-27B outperforms Qwen3.5-397B-A17B (the prior 397-billion-parameter MoE flagship) on three agentic coding benchmarks:
| Benchmark | Qwen3.6-27B | Qwen3.5-397B-A17B | Relative Gain |
|---|---|---|---|
| SWE-bench Verified | 77.2% | 76.2% | +1.0pp |
| SWE-bench Pro | 53.5% | 50.9% | +2.6pp |
| Terminal-Bench 2.0 | 59.3% | 52.5% | +6.8pp |
| SkillsBench | 48.2% | 30.0% | +18.2pp (+77% relative) |
The SkillsBench result - a 77% relative improvement with 14.8x fewer parameters - is the headline. The explanation: Qwen3.6-27B's fully dense architecture and updated training approach outperform an older, larger MoE on task types that benefit from coherent, non-routed inference.
One important caveat: all benchmark runs use Alibaba's internal agent scaffold. Independent third-party verification on production coding tasks was limited as of the release date. Scaffold choice alone can move SWE-bench results by 5–10 percentage points.
- Qwen blog: qwen.ai/blog?id=qwen3.6-27b
- MarkTechPost: marktechpost.com
Mistral Codestral 2 - Code-Specialized at 22B
Mistral released Codestral 2 on April 8, 2026 under Apache 2.0. A 22B dense model purpose-built for code generation with fill-in-the-middle capabilities across 80+ programming languages, including Python, Java, C, C++, JavaScript, and Bash.
Codestral 2 is not a general-purpose model and is not trying to be. It ships with two distinct API endpoints: a FIM completion endpoint accepting prefix and suffix parameters for in-file code completion, and a chat endpoint for conversational code assistance. The FIM mechanism makes it practical for IDE-level integration - completing partial functions, writing tests for existing code, filling gaps without requiring the full file as context.
- Mistral Codestral page: mistral.ai/news/codestral
NVIDIA Ising - The Quantum Outlier
NVIDIA launched Ising on April 14, 2026 - the first open-source family of AI models targeting quantum computing workflows. The framing is different from every other model on this list: Ising is not a language model, it does not compete on NLP benchmarks, and its relevance is for quantum hardware teams rather than application developers.
Two model families:
Ising Calibration - A 35-billion-parameter vision-language model fine-tuned to read experimental measurements from a quantum processing unit (QPU) and infer the calibration adjustments needed to tune it. Reduces calibration time from days to hours when paired with an agent. Calibration has historically been one of the primary bottlenecks to expanding qubit counts on real hardware.
Ising Decoding - Two variants of a 3D convolutional neural network (0.9M and 1.8M parameters) designed for real-time quantum error-correction decoding. Performance: 2.5x faster and 3x more accurate than pyMatching, the most widely used open-source quantum error-correction decoder in active research.
Models are available on GitHub, Hugging Face, and build.nvidia.com, integrated with NVIDIA's CUDA-Q quantum software platform and the NVQLink QPU-GPU interconnect.
Early adopters include Harvard SEAS, Fermi National Accelerator Laboratory, Lawrence Berkeley National Laboratory's Advanced Quantum Testbed, IQM Quantum Computers, and the UK National Physical Laboratory.
- NVIDIA press release: nvidianews.nvidia.com/news/nvidia-launches-ising
- Technical blog: developer.nvidia.com/blog/nvidia-ising
Benchmark Reality Check
Before reading any of these numbers as ground truth, three things to keep in mind.
SWE-bench variants are not interchangeable. SWE-bench Verified (500 human-validated GitHub issues) and SWE-bench Pro (harder, expert-level issues) measure different things. A model scoring 87.6% on Verified and 64.3% on Pro is expected - these are not inconsistent numbers. Comparing a Verified score from one model to a Pro score from another is a category error.
Leaderboard submissions are not always the released model. Meta submitted an experimental Maverick to LMArena and shipped different weights publicly. This is not unique to Meta - lab-submitted leaderboard scores should be treated as upper bounds until independent evaluation on public weights confirms them.
Agent scaffold dominates coding benchmarks. Qwen3.6-27B's results use Alibaba's scaffold. DeepSeek's use DeepSeek's. Claude's use Anthropic's. The scaffold - tool-calling strategy, retry logic, how the model handles partial failures - moves SWE-bench scores by 5–10 percentage points independent of model capability. "Model X at 80.6% on SWE-bench" is more precisely: "model X, running Anthropic's scaffold, at 80.6%." Third-party evaluations using a consistent scaffold across models are the only apples-to-apples comparisons worth trusting.
The Signal Under the Noise
Three things are actually happening in April 2026, underneath the benchmark announcements.
Open source is at frontier quality on coding. DeepSeek V4-Pro at 80.6% SWE-bench Verified under MIT license, GLM-5.1 leading SWE-bench Pro under MIT, Qwen3.6-27B beating a 14.8x larger model - the capability gap that justified paying $5–$30 per million tokens for proprietary APIs has narrowed to a rounding error on code-specific tasks. If your workload is agentic software development, the build-versus-buy calculus changed this month.
Context windows are no longer a differentiator. Scout's 10M context, Maverick's 1M, GPT-5.5's 1M, DeepSeek V4's 1M, Grok 4.20's 2M - the race to "infinite context" is effectively settled at the frontier. The differentiating question has shifted to what the model actually does with 500K tokens of context, not whether it technically supports 1M. Retrieval quality, coherence over long spans, and reasoning fidelity at depth are the new battleground.
The safety-capability tradeoff is now explicit in public policy. Anthropic made the clearest institutional statement in AI lab history: Mythos exists, it is the most capable model ever benchmarked, and it is not shipping publicly because the offensive capability risk is too high. Project Glasswing is a bet that a dangerous model can be used by defenders to prevent even more dangerous use by attackers - and that the controlled rollout buys enough time for the industry to harden its defenses. Whether that logic holds under competitive pressure from labs without the same risk calculus is the open question going into May.
Sources
- Anthropic Mythos Preview
- Project Glasswing
- Fortune on Mythos
- TechCrunch on Mythos
- Schneier on Security
- Anthropic Claude Opus 4.7
- VentureBeat on Opus 4.7
- OpenAI GPT-5.5
- TechCrunch on GPT-5.5
- GPT-5.5 System Card
- xAI Grok 4
- Meta Llama 4 blog
- Llama 4 on Hugging Face
- Gemma 4 blog
- Google Open Source blog on Gemma 4
- Gemma 4 on Hugging Face
- GLM-5.1 on Hugging Face
- Constellation Research on GLM-5.1
- DeepSeek V4 API docs
- DeepSeek V4-Pro on Hugging Face
- Bloomberg on DeepSeek V4
- The Next Web on DeepSeek V4
- Qwen3.6-27B blog
- MarkTechPost on Qwen3.6-27B
- Mistral Codestral
- NVIDIA Ising press release
- NVIDIA Ising technical blog